『問題解決型』ハードウェアメーカー
ファナティック
-
- ファナティックの特長 ファナティックの特長
- /
- 製品&ソリューション 製品&ソリューション
- /
- 導入事例 導入事例
- /
- 最新ニュース 最新ニュース
- /
- ファナティックレポート ファナティックレポート
- /
- サポート サポート
- /
- 会社案内 会社案内
- /
- 採用情報 採用情報
AIの基盤づくりをあきらめていませんか。
幅広い製品のご提案からセットアップ・保守までサポートします。
製造業におけるDX推進や工場のスマートファクトリー化が進むいっぽう、業界全体では人手不足への対処や技術伝承も課題となっています。
このようななかで注目されているのがAIであり、数多くの活用事例が見られるようにもなってきました。
生産効率の大幅な改善や収益の拡大のため、今後ますますAI活用の重要性が増していくと考えられます。

さまざまな活用例を参考に、マネジメント層や業務部門からAI導入の推進を求められた場合、情報システム部門などのIT管理担当者が取り組まなければならないのが、AIの基盤づくり(インフラ構築)であり、そのための課題を押さえておく必要があります。

既存ITインフラへの
AIソリューションの統合

仮想環境での
GPUパフォーマンス調査

GPU製品とハードウェアの
選定と調達、保守サポート
ファナティックは、AIに欠かせない重要パーツを提供する
GPUベンダーのNVIDIA社のパートナー(NPN Partner Network)メンバーとして、
教育機関や公的機関のほか数多くの法人にGPU搭載ワークステーションやサーバーを提供しています。
お客様の要件にあわせたカスタム提案からシステムのサービスインまで、さまざまなご要望にお応えします。
既存IT基盤への統合~仮想化
「NVIDIA AI Enterprise」は、さまざま産業分野の企業がITインフラとして保有するデータセンター上で、NVIDIA製GPUを用いたAI(人工知能)の開発環境を容易に運用できるようにするソフトウェアスイートです。VMwareや Red Hat の仮想化およびコンテナ オーケストレーション プラットフォーム上で実行できるよう認定、サポートされており、今日のマルチおよびハイブリッドクラウド環境に必要な柔軟な展開を可能にします。

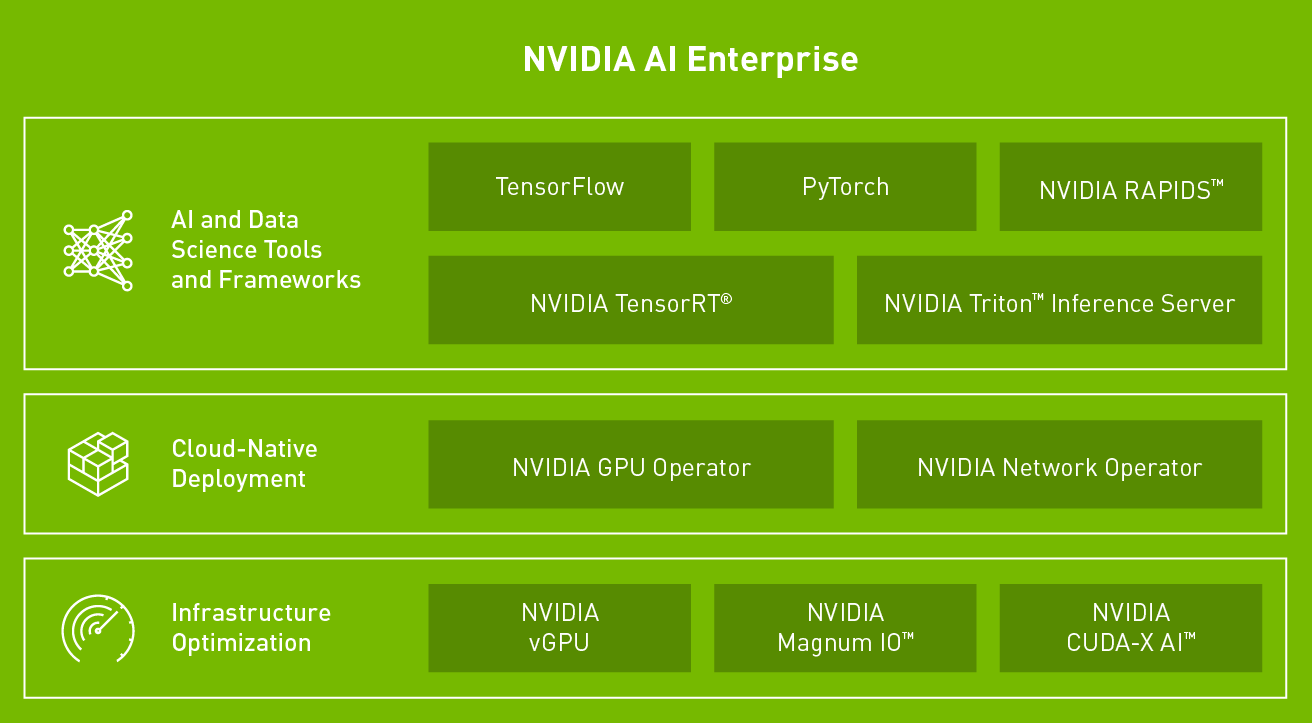
業界をリードするKubernetesを搭載したハイブリッドクラウドソリューションであるRed Hat OpenShiftと、NVIDIA AI Enterpriseとの組み合わせで、多様なAIのユースケースを加速させる拡張性の高いプラットフォームを実現します。Red Hat Enterprise Linuxを実行する共同認定ベアメタルシステム、VMware vSphere上の仮想環境、CPUのみのシステムに、オンプレミスとパブリッククラウドに関わらず柔軟な導入が可能です。
NVIDIA AI Enterpriseは、VMware vSphereとVMware Cloud Foundationで実行できることが認定されているため、使い慣れたインフラストラクチャ上の仮想化データセンターにAIをデプロイして、シンプルに管理できます。NVIDIA AI Enterpriseは、GPU対応のクラウドサービスの運用と管理を行うVMware Cloud Directorにも対応しています。VMware vSphereは、コンテナの展開のためのRed Hat OpenShiftでもサポートされています。
AI活用で重要な計算処理能力が、仮想化プラットフォームでも確保できるのだろうか、物理環境で使用する場合に比べて能力が落ちてしまうのではないかと心配されるお客様の不安を解消するため、ファナティックでは、それぞれの環境を構築して比較検証を行いました。パフォーマンスはほぼ変わらないと言えるのではないでしょうか。
AI活用で重要な計算処理能力が、仮想化プラットフォームでも確保できるのだろうか、物理環境で使用する場合に比べて能力が落ちてしまうのではないかと心配されるお客様の不安を解消するため、ファナティックでは、それぞれの環境を構築して比較検証を行いました。パフォーマンスはほぼ変わらないと言えるのではないでしょうか。
| b512 | b384 | b256 | b192 | |
| 基準ケース(fp16) | 1525.6 | 1522.6 | 1490.7 | 1495.9 |
| 比較ケース VM/Docker比 | 1.0 | 0.99 | 0.95 | 0.95 |


PCI-E Gen4ベースのNVIDIA A100、A40、A30をサポートするNVIDIA認定のサーバーやワークステーションを提供、お客様のニーズにあわせて1Uから4Uまでをご用意し、最大8GPUをサポートします。
また、高速かつ低遅延のネットワーク接続を提供するNVIDIA Connectx-7 Smart-NICやNVDIA BlueField DPUのご提案も可能です。

| A100 | A40 | A30 | |
| GPUアーキテクチャ | NVIDIA Ampereアーキテクチャ | NVIDIA Ampereアーキテクチャ | NVIDIA Ampereアーキテクチャ |
| 倍精度浮動小数点演算(FP64) | 9.7 TFLOPS | 非公開 | 5.2 TFLOPS |
| 単精度浮動小数点演算(FP32) | 19.5 TFLOPS | 37.4 TFLOPS | 10.3 TFLOPS |
| 半精度浮動小数点演算(FP16) | 312 TFLOPS | 149.7 TFLOPS | 165 TFLOPS |
| FP64 Tensor Core演算性能 | 19.5 TFLOPS | 非公開 | 10.3 TFLOPS |
| TF32 Tensor Core演算性能 | 156 TFLOPS | 74.8 TFLOPS | 82 TFLOPS |
| BFLOAT16 Tensor Core演算性能 | 156 TFLOPS | 74.8 TFLOPS | 82 TFLOPS |
| INT8 Tensor Core演算性能 | 624 TOPS | 299.3 TOPS | 330 TOPS |
| INT4 Tensor Core演算性能 | 1,248 TOPS | 598.7 TOPS | 661 TOPS |
| メモリバンド幅 | 1555GB/s / 1935GB/s | 696 GB/s | 933 GB/s |
| メモリインターフェース | 5120-bit | 384-bit | 3072-bit |
| メモリサイズ | 80GB HBM2e | 48 GB GDDR6 ECC付き | 24GB HBM2 |
| NVLink | YES 600 GB/sec(双方向) 2基のA100間を接続 |
YES 112.5 GB/sec(双方向) 2基のA40間を接続 |
YES 200 GB/sec(双方向) 2基のA30間を接続 |
| CUDAコア | 6,912 | 10,752 | 非公開 |
| Tensorコア | 432(3rd Gen) | 336(3rd Gen) | 非公開 |
| RTコア | - | 84(2nd Gen) | 非公開 |
| PCI-E | PCIe 4.0x16 | PCIe 4.0x16 | PCIe 4.0x16 |
| TDP | 400w | 300w | 165w |
| 補助電源コネクタ | 1x8-pin CPU | 1x8-pin CPU | 1x8-pin CPU |

お届けするサーバーやワークステーションには、UbuntuやRedhatなどOSのインストール、CUDA、NVIDIA NGC、NVIDIA Docker、Tensorflow、Pytorch、kubernetesなどAI、ディープラーニング用の各種コンテナやライブラリのセットアップ代行も行っております。
1年間の無償センドバック保証を標準でご用意。さらにオプションで最長5年の長期保証※も可能です。また、オンサイトによる保守やテクニカルサポートなどでお客様の運用をバックアップいたします。
※一部製品を除く、詳しくは営業担当までお問い合わせください。
