『問題解決型』ハードウェアメーカー
ファナティック
-
- ファナティックの特長 ファナティックの特長
- /
- 製品&ソリューション 製品&ソリューション
- /
- 導入事例 導入事例
- /
- 最新ニュース 最新ニュース
- /
- ファナティックレポート ファナティックレポート
- /
- サポート サポート
- /
- 会社案内 会社案内
- /
- 採用情報 採用情報
プライベートLLM・RAGの運用基盤を支える、
企業におけるAI活用が急速に広がっています。用途はデータ解析、自動化、予測分析など多岐にわたり、ビジネスの効率化や新しい価値創出に大きなインパクトをもたらしています。とくに高性能GPUの登場により、AIモデルのトレーニングや実行が高速化され、より複雑な問題解決が可能となりました。
テキスト向けAIモデルにおいて欠かせないLLM(大規模言語モデル)では、自然言語処理の高度なタスクを処理するためのトレーニングや実行において、LLMの性能や効率に大きな影響を及ぼす高性能GPUの選択が不可欠であり、かつ社内データベースと連携させるRAGで回答精度を高める方式が注目されており、セキュリティの観点からはオンプレミスでの運用が求められています。
このような要件にお応えする 最新のNVIDIA®高性能GPU製品とオンプレミス環境を構築するファナティックのオーダーメイド・サーバーをご紹介します。


進化したNVIDIA Hopper™アーキテクチャをベースとするNVIDIA H200は、141GBのHBM3eメモリと毎秒4.8テラバイトのメモリ帯域幅を備え、H100と比較してメモリ容量が約2倍、帯域幅が約1.4倍に向上しています。これにより、生成AIや大規模言語モデル(LLM)の学習と推論を飛躍的に加速します。

NVIDIA Hopper™アーキテクチャを採用したNVIDIA H100は、94GBのHBM3メモリと毎秒3.9テラバイトのメモリ帯域幅を備え、大規模言語モデル(LLM)の学習と推論を最大30倍高速化します。第4世代のTensorコアは、FP8精度で混合エキスパート(MoE)モデルのトレーニングを最大9倍高速化します。
| NVIDIA H200 NVL | NVIDIA H100 NVL(※1) x2 NVLink™ 接続 |
|
|---|---|---|
| FP64 | 30 TFLOPS | 68 TFLOPS |
| FP64 Tensor コア | 60 TFLOPS | 134 TFLOPS |
| FP32 | 60 TFLOPS | 134 TFLOPS |
| TF32 Tensor コア | 835 TFLOPS | 1,979 TFLOPS(※2) |
| BFLOAT16 Tensorコア | 1,671 TFLOPS | 3,958 TFLOPS(※2) |
| FP16 Tensorコア | 1,671 TFLOPS | 3,958 TFLOPS(※2) |
| FP8 Tensorコア | 3,341 TFLOPS | 7,916 TFLOPS(※2) |
| INT8 Tensorコア | 3,341 TFLOPS | 7,916 TFLOPS(※2) |
| GPUメモリ | 141 GB | 188GB |
| GPUメモリ帯域幅 | 4.8TB/s | 7.8TB/s(※3) |
| デコーダー | 7 NVDEC 7 JPEG |
14 NVDEC 14 JPEG |
| 最大熱設計電力(TDP) | UP to 600W (configurable) |
2x 350-400W (configurable) |
| マルチインスタンス GPUs | Up to 7 MIGs@ 16.5GB each |
Up to 14 MIGs@ 12GB each |
| フォームファクター | PCIe dual-slot air-cooled |
2x PCIe dual-slot air-cooled |
| 相互接続 | 2 -or 4-way NVIDIA NVLink bridge:900GB/s Per GPU PCIe Gen5: 128GB/s |
NVLink 600GB/s PCIe Gen5: 128GB/s |
| NVIDIA AI Enterprise | Included | Included |
※1:参考仕様、仕様は変更される場合があります。
※2:With sparsity(疎性あり)
※3:HBM 帯域幅の総計
当社ではベンチマークテストで取得したデータを参考に、GPU製品の選定やサーバー構成をご提案しています。
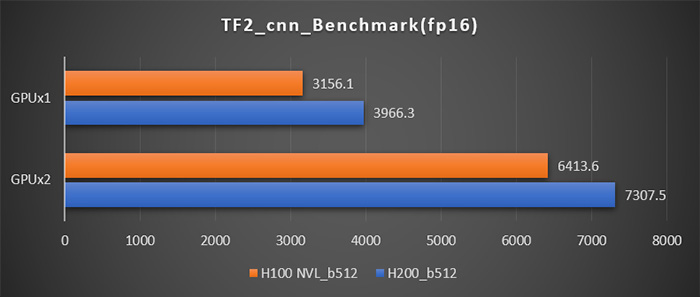
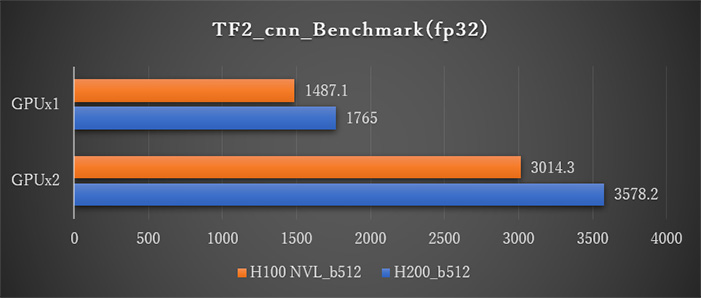
H200 とH100 NVLとの比較結果(1基および2基搭載時の画像処理速度(image/sec))。
Tensorflowの学習ベンチマーク結果では、H200とH100 NVLの比較では最大1.25倍のパフォーマンス向上が見られます。
ファナティックはGPUサーバーの業界のリーダーとして、企業や大学・研究機関向けにお客様の課題を解決するオーダーメイド製品を20年以上に渡って提供し続けています。
NPN(NVIDIAパートナーネットワーク)メンバーとしての強固なパートナーシップを活かし、早い段階での新製品の検証を行うことでお客様の製品選定の時間や工数削減に貢献するとともに、ネットワーク機器やストレージ、ラックなども含めたトータルでのご提案が可能です。
出荷製品の詳細な記録によるトレーサビリティ、24時間365日オンサイト、センドバックの保守体制で充実したサポート体制で導入から運用までをバックアップします。
NVIDIA H100 NVL または NVIDIA RTX™ 6000 AdaなどハイエンドGPUを8基搭載可能。画像認識や自然言語処理などのワークロード用に開発された複雑かつ大規模なAIモデルの学習などに最適です。

東大阪の製造拠点であるプロダクションセンターでは、構成にもとづいた製造指図書から製造部門が組み立てと検証を行います。またここでは技術部門が前述したベンチマーク情報の取得や稼働音測定なども行っています。
これらの情報は、お客様に構成の提案を行っている営業部門にタイムリーに集められるため、製造の進捗状況はもちろん、テクニカルな情報も集約されますので、構成した製品に関する詳細かつ具体的な内容をお届けすることを可能にしています。

すぐに使える状態で納品してほしいというご要望にお応えできるよう、ファナティックではディープラーニング環境のセットアップをサポートしています。これにはエヌビディア社からリリースされる最新のツールや情報のキャッチアップが欠かせませんので、技術部門が中心となって密なコミュニケーションを図っています。
このような体制に大変重要な役割を果たしているのが、エヌビディア社のNPN(NVIDIA Partner Network)で、ファナティックはこの制度に参画することでディープラーニングの活用を、より多くのお客様にご提案しています。
