『問題解決型』ハードウェアメーカー
ファナティック
-
- ファナティックの特長 ファナティックの特長
- /
- 製品&ソリューション 製品&ソリューション
- /
- 導入事例 導入事例
- /
- 最新ニュース 最新ニュース
- /
- ファナティックレポート ファナティックレポート
- /
- サポート サポート
- /
- 会社案内 会社案内
- /
- 採用情報 採用情報
2024.11.06 ベンチマークレポート
NVIDIA® H100のNVLink対応版である、NVIDIA® H100 NVLの学習ベンチマークの結果をレポートします。
NVLink非対応のH100とのベンチマークで、1基および2基搭載で画像処理速度(image/sec)を比較しました。また、H100 NVL4基搭載時のテスト結果もあわせて検証しましたのでぜひご覧ください。
注)ベンチマーク取得時期にともない、ドライバ環境などが異なりますのであらかじめご了承ください。
※2024年12月10日追記:H100 NVL8基搭載時のテスト結果を追加掲載いたしました。
[NVIDIA® H100 NVLについて]
H100 NVLは、2024年3月にリリースされた、NVIDIA® Hopperアーキテクチャを採用した大規模AI向けGPUです。
H100 NVLは、2基をNVLinkで接続することにより、最大188GB(94GB x 2)のメモリ空間を実現します。
[NVIDIA® H100 NVL/NVIDIA® H100仕様]
| NVIDIA® H100 NVL | NVIDIA® H100 | |
| メモリー | 94GB | 80GB |
| メモリー帯域 | 3.9TB/s | 2TB/s |
| 消費電力 | 300~350W | 300~350W |
| サイズ | 2Slot | 2Slot |
[総評]
H100と比較してH100 NVLは、より高いパフォーマンスであるという結果が得られました。画像処理速度で最大1.3倍のスコアを確認いたしました。
また、バッチサイズもfp16で2048、fp32で1024での演算が可能となっております。より大規模なモデルでの活用が期待できます。
[詳細]
■TensorFlow 学習ベンチマーク(ResNet50)
| NVIDIA® H100 NVL | NVIDIA® H100 | |
| OS | Ubuntu 24.04.1 | Ubuntu 22.04.1 |
| ドライバ | 560.35.03 | 535 |
| Docker | 24.08-tf2-py3 (TensorFlow2) |
23.02-tf2-y3 (TensorFlow2) |
| CUDA | 12.6.2 | 12.2 |
■H100 NVL とH100との比較結果(1基および2基搭載時の画像処理速度(image/sec))
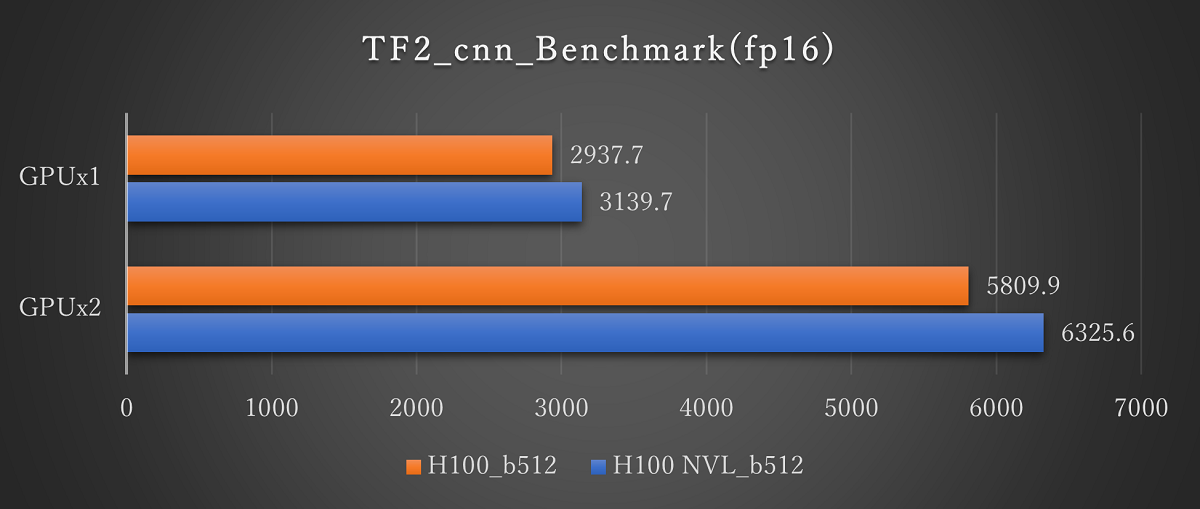
ResNet50(fp16 Batch512)※画像をクリックすると拡大します。
ResNet50(fp32 Batch512)※画像をクリックすると拡大します。
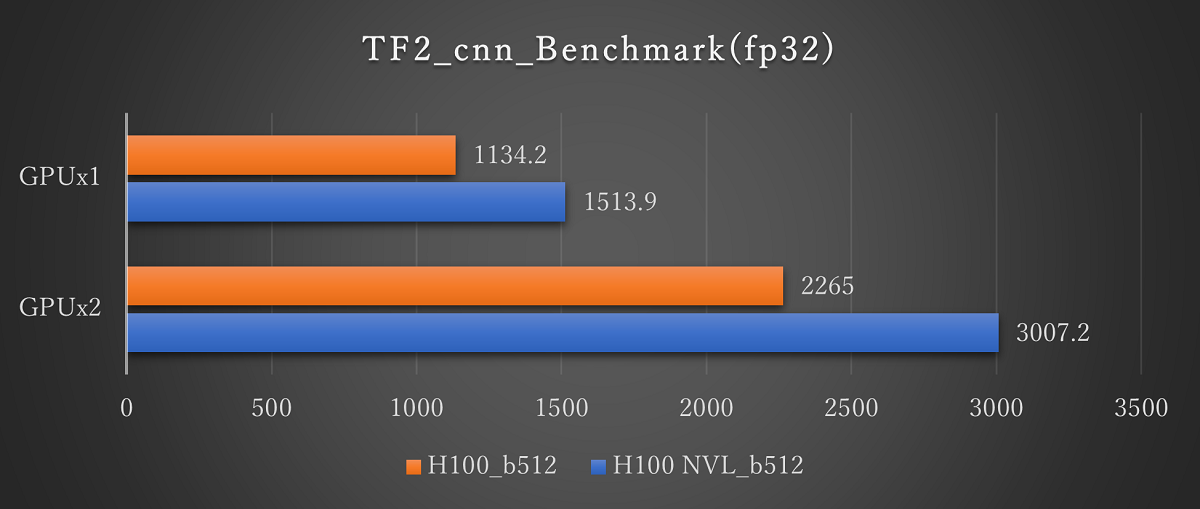
Tensorflowの学習ベンチマーク結果では、H100 NVLとH100の比較では最大1.3倍のパフォーマンス向上が見られます。fp16では約1.1倍であるのに対してfp32では約1.3倍と精度が上がるほどパフォーマンスの向上がみられました。
■H100 NVLの結果(1基から4基搭載時)
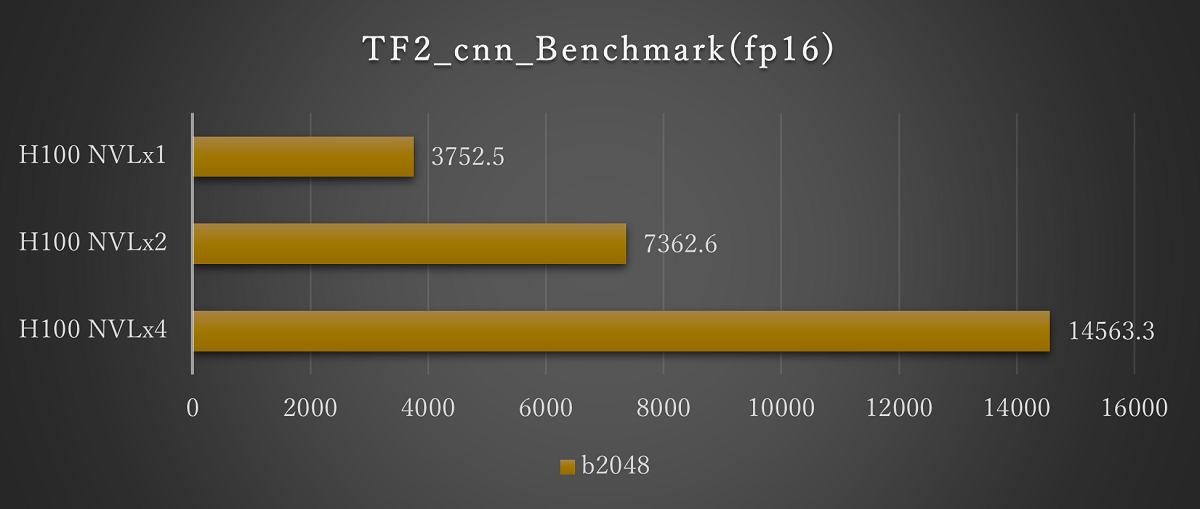
ResNet50(fp16 Batch2048)※画像をクリックすると拡大します。
ResNet50(fp32 Batch1024)※画像をクリックすると拡大します。
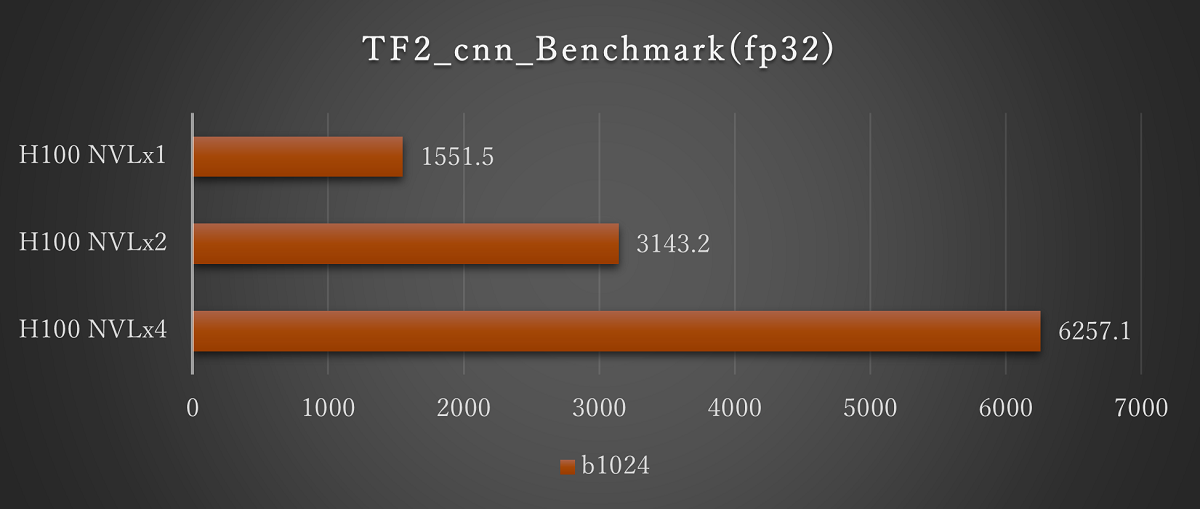
H100 NVLのマルチGPUでの評価として、1基から4基での評価を実施しました。いずれも基数に応じてスコアが上昇し、搭載数に応じた結果が期待できます。
バッチサイズについては、今回のH100 NVLではfp16では2048まで、fp32では1024まで実行できることを確認しています。H100 NVLでは、より大規模なモデルでの評価が期待できます。
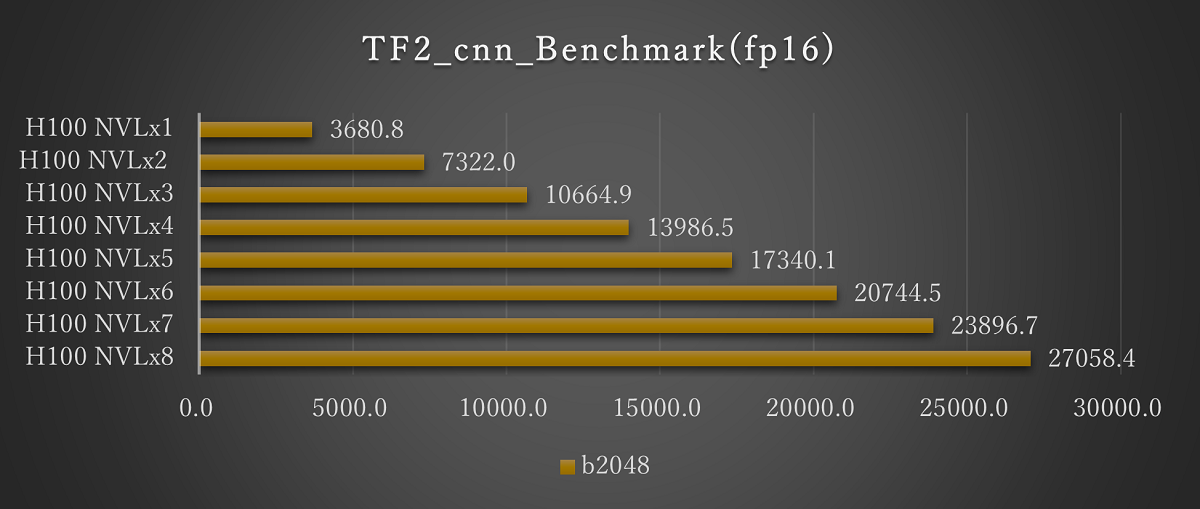
■H100 NVLの結果(1基から8基搭載時)
ResNet50(fp16 Batch2048)※画像をクリックすると拡大します。
ResNet50(fp32 Batch1024)※画像をクリックすると拡大します。
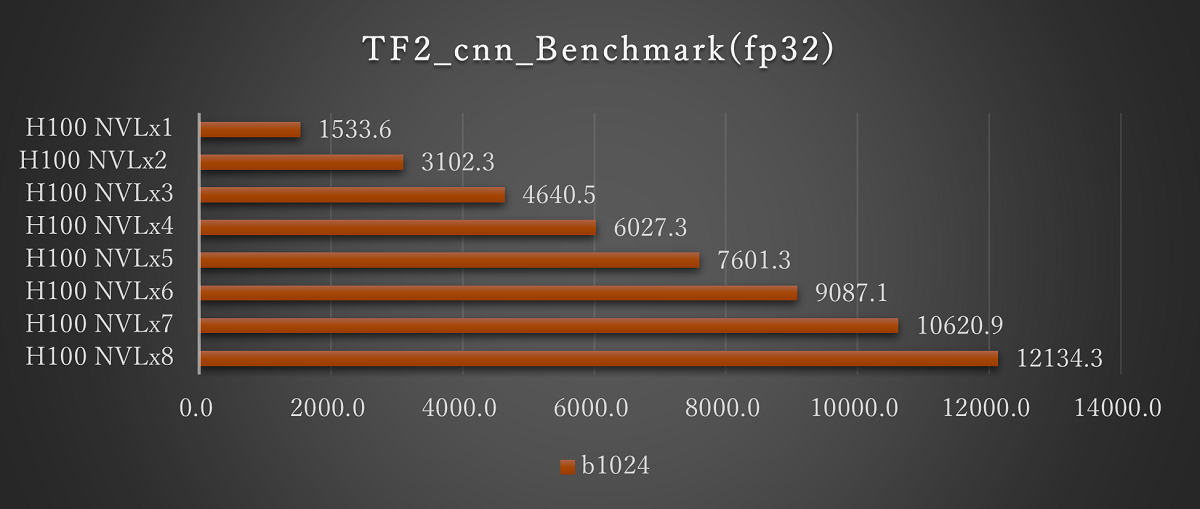
H100 NVLのマルチGPUでの評価として、1基から8基での評価を実施しました。いずれも基数に応じてスコアが上昇し、搭載数に応じた結果が期待できます。
バッチサイズについては、4基での評価と同様にH100 NVLにおいてfp16では2048まで、fp32では1024まで実行できることを確認しています。H100 NVLでは、より大規模なモデルでの評価が期待できます。
[まとめ]
H100 NVLのベンチマークを実施いたしました。ハイエンドGPUとなっており特に大規模なモデルで成果が期待できます。H100とほぼ同じ価格でありながらパフォーマンスが向上していますので、価格性能比でH100 NVLの選択は十分お薦めできるといえます。ご検討の方はお気軽にお問い合わせください。
◆年度末特別価格のご案内◆
NVIDIA® H100 NVLを特別価格でご提供中です。ご購入を検討の方はこの機会にぜひお問い合わせください。