『問題解決型』ハードウェアメーカー
ファナティック
-
- ファナティックの特長 ファナティックの特長
- /
- 製品&ソリューション 製品&ソリューション
- /
- 導入事例 導入事例
- /
- 最新ニュース 最新ニュース
- /
- ファナティックレポート ファナティックレポート
- /
- サポート サポート
- /
- 会社案内 会社案内
- /
- 採用情報 採用情報
2025.03.10 ベンチマークレポート
H200は4.8 (TB/s) で 141 (GB) の HBM3e メモリを提供する初の GPU です。H200の学習ベンチマークの結果をご提供します。
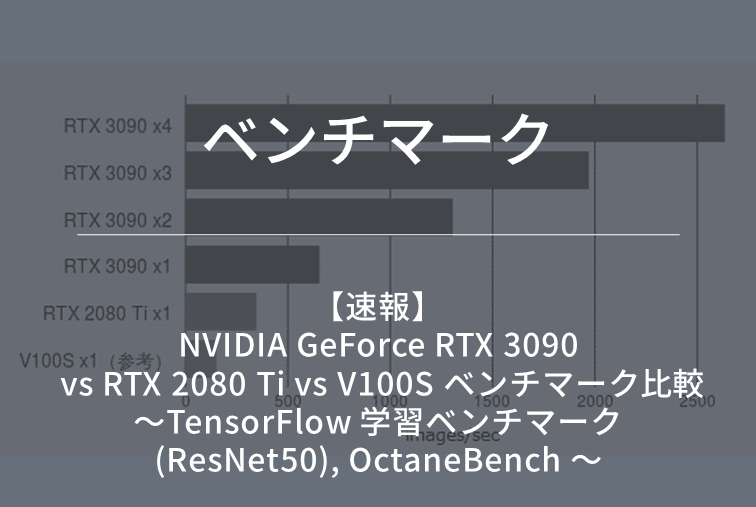
NVLink対応のH100NVLとのベンチマークで、1基から4基搭載で画像処理速度(image/sec)を検証しました。
注)ベンチマーク取得時期にともない、ドライバ環境などが異なりますのであらかじめご了承ください
H200は、2024年3月にリリースされた、NVIDIA Hopper アーキテクチャを採用した大規模AI向けGPUです。
毎秒 4.8 テラバイト (TB/s) で 141 ギガバイト (GB) の HBM3e メモリを提供します。
| H200 | H100 NVL | |
|---|---|---|
| メモリ | 141GB | 94GB |
| メモリ帯域 | 4.8TB/s | 3.9TB/s |
| 消費電力 | 700W | 300-350W |
| サイズ | SXM | 2Slot |
H100NVLと比較してH20は、より高いパフォーマンスであることが確認できました。画像処理速度で最大1.25倍のスコアを確認いたしました。
また、バッチサイズもfp16で2048、fp32で1536での演算が可能となっております。より大規模なモデルでの活用が期待できます。
| H200 SXM / H100 NVL | |
|---|---|
| OS | Ubuntu 24.04.1 |
| Driver | 560.35.03 |
| Docker | 24.08-tf2-py3 (TensorFlow2) |
| CUDA | 12.6.2 |
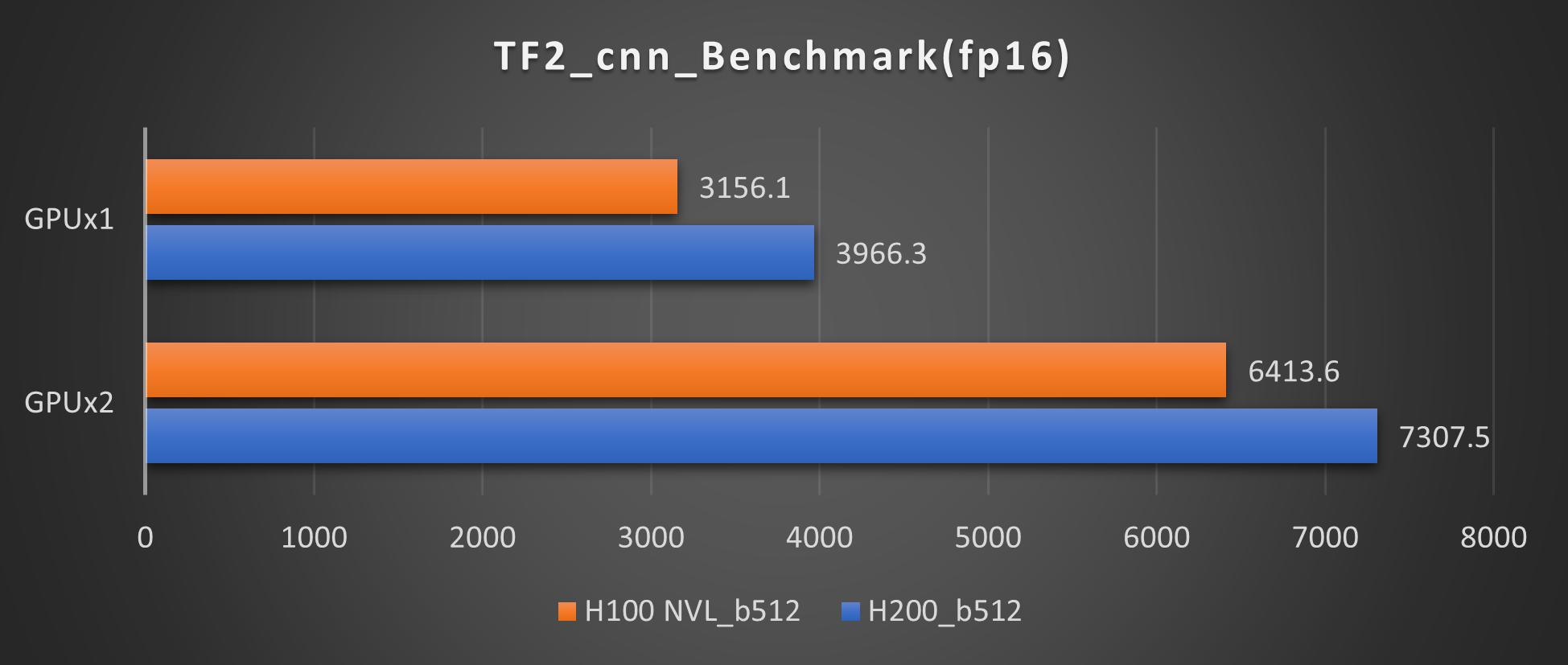
ResNet50(fp16 Batch512)
ResNet50(fp32 Batch512)
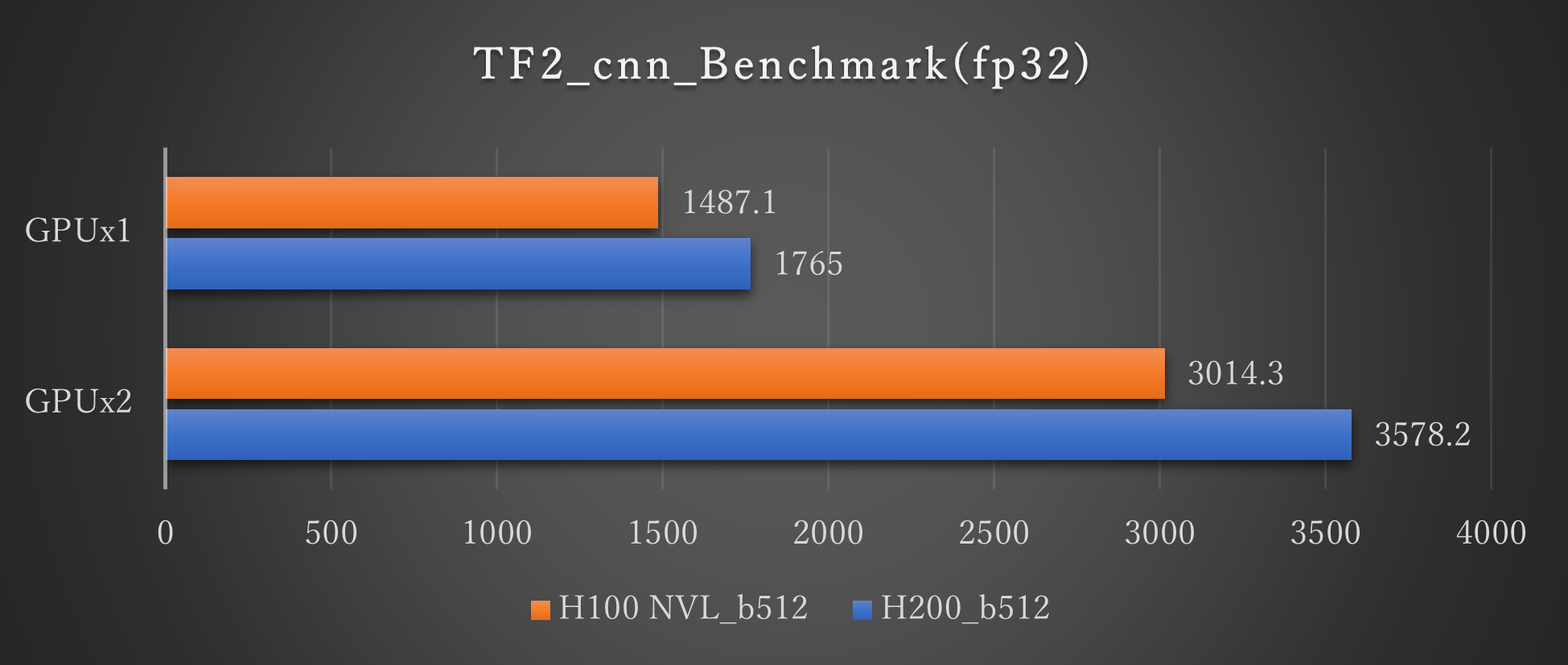
Tensorflowの学習ベンチマーク結果では、H200とH100 NVLの比較では最大1.25倍のパフォーマンス向上が見られます。
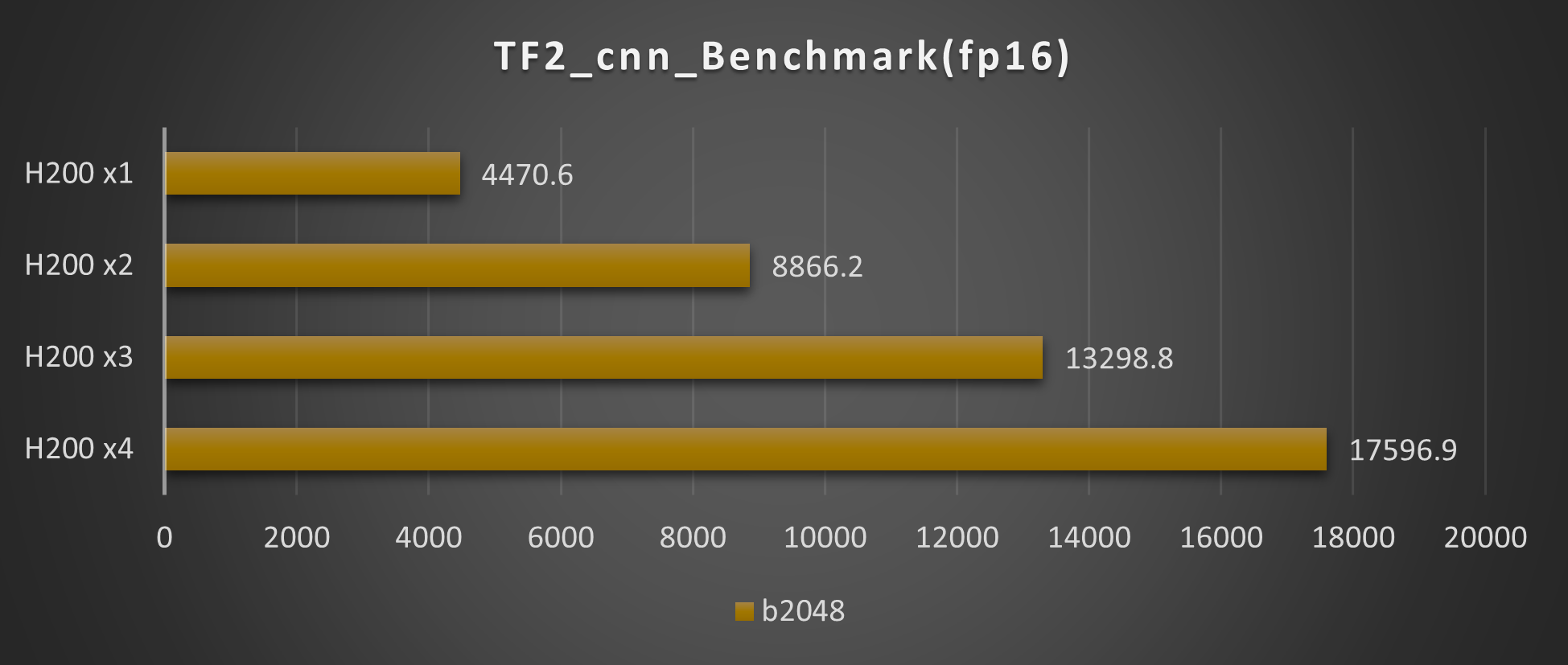
ResNet50(fp16 Batch2048)
ResNet50(fp32 Batch1536)

H100 NVLのマルチGPUでの評価として、1基から4基での評価を実施しました。いずれも基数に応じてスコアが上昇し、搭載数に応じた結果が期待できます。
バッチサイズについては、今回のH200ではfp16では2048まで、fp32では1536まで実行できることを確認しています。H200では、より大規模なモデルでの評価が期待できます。
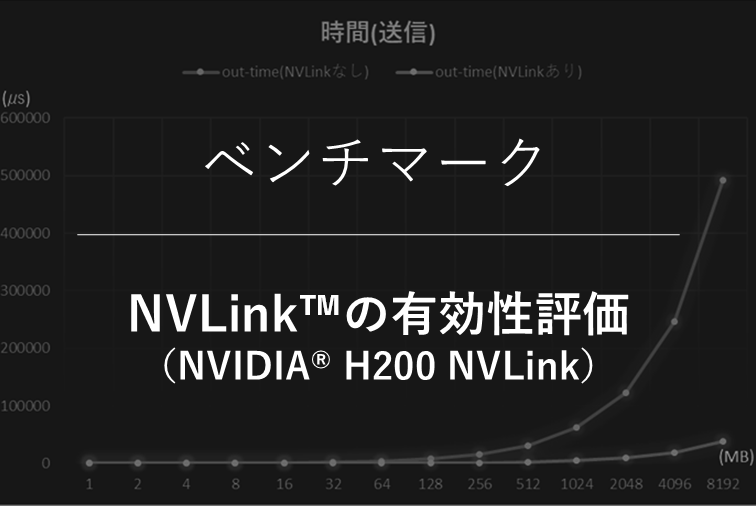
H200のベンチマークを実施いたしました。ハイエンドGPUとなっており特に大規模なモデルで成果が期待できます。是非お問い合わせ下さい。
また、引き続きH200のNVLinkの効果の評価を実施しております。別途ご報告いたします。ご期待ください。