『問題解決型』ハードウェアメーカー
ファナティック
-
- ファナティックの特長 ファナティックの特長
- /
- 製品&ソリューション 製品&ソリューション
- /
- 導入事例 導入事例
- /
- 最新ニュース 最新ニュース
- /
- ファナティックレポート ファナティックレポート
- /
- サポート サポート
- /
- 会社案内 会社案内
- /
- 採用情報 採用情報
2019.04.18 ベンチマークレポート
NVIDIA® Turing™のアーキテクチャを採用したGPU(Turing世代)であるNVIDIA® Geforce® RTX 2080 TiとNVIDIA® TITAN RTX™を使用し、ディープラーニングのフレームワークである「Chainer」でImageNetの画像の一部を使用し、学習のベンチマークを実施しました。
前世代のGPU(Pascal世代)であるGTX 1080 TiとTuring世代を比較、GPUの枚数を最大10枚で学習した結果、TensorCoreを使用した結果をご報告いたします。また、2080 Ti 5枚における動作環境評価の結果もあわせてご報告いたします。
●学習に使用したGPU
| 世代 | |
| Pascal | Geforce GTX 1080 Ti ×1 |
| Turing | Geforce RTX 2080 Ti ×10 |
| TITAN RTX ×1 |
●GPUのスペック表
| GTX 1080 Ti | RTX 2080 Ti | TITAN RTX | |
| アーキテクチャ | Pascal | Turing | Turing |
| GP102 | TU102 | TU102 | |
| 単精度FP性能 [TFLOPS] | 11.3 | 13.4 | 16.3 |
| DeepLearning Tensor性能 [TFLOPS] | – | 107.6 | 130 |
| CUDAコア | 3584 | 4352 | 4608 |
| RTコア | – | 68 | 72 |
| Tensorコア | – | 544 | 576 |
| クロック [MHz] | 1480 | 1350 | 1350 |
| クロック(boost) [MHz] | 1582 | 1545 | 1770 |
| メモリバンド幅 [GB/s] | 484 | 616 | 672 |
| メモリサイズ [GB] | 11 | 11 | 24 |
| メモリタイプ | GDDR5X | GDDR6 | GDDR6 |
| 電力 [W] | 250 | 250 | 280 |
●学習環境
学習に用いたフレームワークはChainerを使用しました。プログラムはGithubに公開されているものを利用しました。
環境は下記です。
| OS | Ubuntu 16.04.5 LTS |
| CUDA | 10 |
| cuDNN | 7.3 |
| NCCL | 2.3.7 |
| Chainer | 4.5.0 |
| Cupy | 4.4.1 |
| Python | 3.5 |
| 画像データ/画像数 | ImageNet/181665 (画像サイズ256×256) |
| ネットワーク | ResNet-50 |
| 学習プログラム(examples/imagenet) | train_imagenet.py |
| train_imagenet_data_parallel.py | |
| Epoch | 10 |
※ImageNetの画像の一部を使用し、trainingとvalidation =8:2の比率にして実施しました。
上記の環境を使用し、学習率は考慮せず、Epoch 10まで学習させた時の実行時間を測定しました。そして、画像数を実行時間で割った値をimages/secとし、スループットを算出しました。スループットが高いほど、高速化されていることを表しています。
1080 Ti、2080 Ti、TITAN RTXの実行時間を測定しました。1080 Tiと2080 Tiはメモリを最大限使用した場合、バッチサイズ105まで実行することができました。TITAN RTXは255まで実行することができました。256はメモリ不足で実行できませんでした。デフォルトのバッチサイズ32と合わせて測定結果を下記に示します。
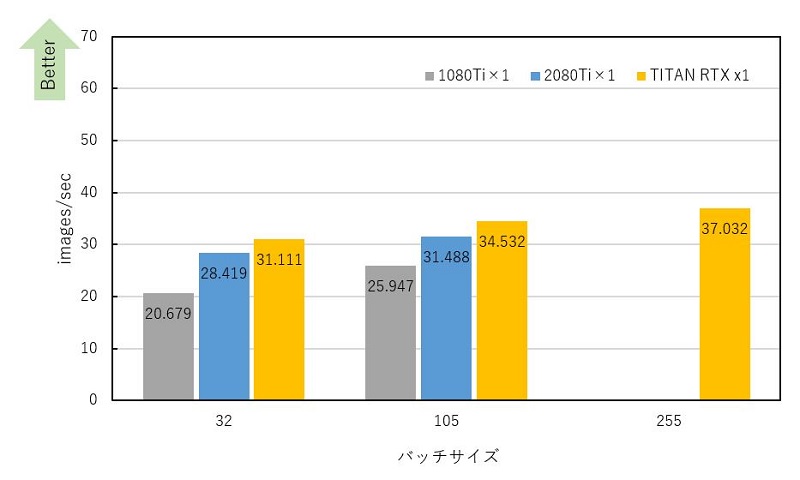
バッチサイズ32、105どちらもPascal世代の1080 Tiに比べ、Turing世代の2080 TiとTITAN RTXは高速化されていることを確認できました。同GPUを異なるバッチサイズで比較するとバッチサイズを大きくすることで高速化がされることも確認しました。TITAN RTXは2080 Tiの約2倍のメモリサイズである24 GBあるため、バッチサイズ255まで実行でき、バッチサイズ105より性能は高くなりました。
バッチサイズ32と各GPUのメモリ最大限使用したバッチサイズにおける1080 Tiを基準とした場合のスループットの比率、2080 Tiを基準とした場合のスループット比率を計算すると下記のようになっていました。
スループットの比較(バッチサイズ= 32)
| GPU | 比率(対1080 Ti) | 比率(対2080 Ti) |
| 1080 Ti | 1 | 0.7 |
| 2080 Ti | 1.4 | 1 |
| TITAN RTX | 1.5 | 1.1 |
スループットの比較(メモリ最大限使用したバッチサイズ)
| GPU | メモリサイズ[GB] | バッチサイズ | 比率(対1080 Ti) | 比率(対2080 Ti) |
| 1080 Ti | 11 | 105 | 1 | 0.8 |
| 2080 Ti | 11 | 105 | 1.2 | 1 |
| TITAN RTX | 24 | 255 | 1.4 | 1.2 |
アーキテクチャの変更だけでなく、CUDAコアの増加などハードウェア面の性能向上によって、1080 Tiから2080 Ti、TITAN RTXは各々1.4 倍、1.5倍の高速化されたと考えられます。メモリを最大限使用することにより、TITAN RTXは2080 Tiの1.2倍高速化できる結果となりました。
2080 TiでマルチGPUのデータ並列を使用し、学習時間を測定しました。GPUは最大10枚まで使用し検証しました。データ並列のため、各GPUが各々実行バッチサイズで学習をします。そのため、実際の実行バッチサイズは「バッチサイズ×GPUの枚数」です。例えば、バッチサイズ64でGPU 4枚で実行したときの実行バッチサイズは256 (64×4)となります。バッチサイズ64の測定結果及びGPU 1枚に対する性能比を下記に示します。
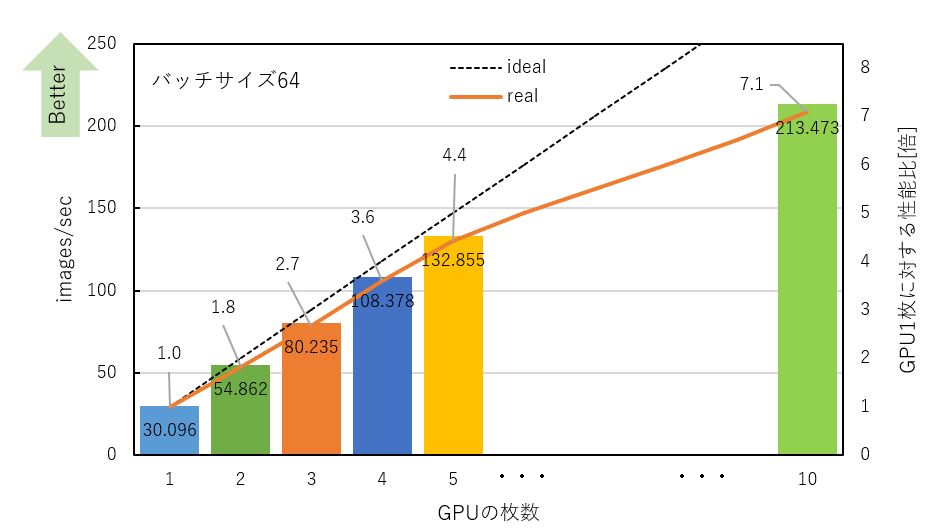
GPUの枚数を増やすことで性能はスケールし、高速化されることを確認しました。1枚から10枚に変化させた場合は7.1倍高速化しました。
理想的にスケールした場合のidealと比較すると、GPUの枚数が増えるほど性能に差がでました。これはCPUのオーバーヘッドやGPU同士の通信時間の影響と考えられます。GPUの枚数を増やすことで学習時間の高速化は確認できましたが、学習率は低下していました。学習率を考慮する場合、GPUの枚数が増えるほど、Epoch数を増やして学習させる必要があります。Chainerの開発を行っている株式会社Preferred Networksの記事[1][2]でマルチノード向けの分散深層学習向けのChainerの追加パッケージであるChainerMNを使用することで、リニアにスループットが向上するだけでなく、学習率の精度も保てるという発表がありました。今回測定しておりませんが、ChainerMNを使用することでChainer単体での測定結果と比べ学習率を考慮した場合にも性能がidealに近づく可能性があります。今後評価していきたいと考えております。
[1]ChainerMNによる分散深層学習の性能について https://research.preferred.jp/2017/02/chainermn-benchmark-results/
[2] 分散深層パッケージChainerMN公開 https://research.preferred.jp/2017/05/chainermn-beta-release/
Volta世代以降、高速化機構の1つとしてTensorCoreがあります。2080 Ti、TITAN RTXでTensorCoreを有効にした場合について検討しました。ChainerでTensorCoreの高速化効果を得るためのテクニックが2018年12月に資料公開されています[3]。その高速化テクニックには大きく分けてcuDNNとChainerの高速化があります。
今回の測定では、TensorCoreを使うための最初のステップであるcuDNNの高速化(cudnn autotune、cuDNNのワークスペース設定(512*1024*1024)、cuDNNの高速Batch Normalization)を適用し、検証しました。Chainerの高速化テクニックは適用していないため、全ての計算部にTensorCore (fp16)が使われた結果となります。また、学習率の考慮はせず、学習時間、スループットのみの性能結果となります。
下記に、TensorCoreが未搭載の1080 Tiと合わせて測定結果を示します。
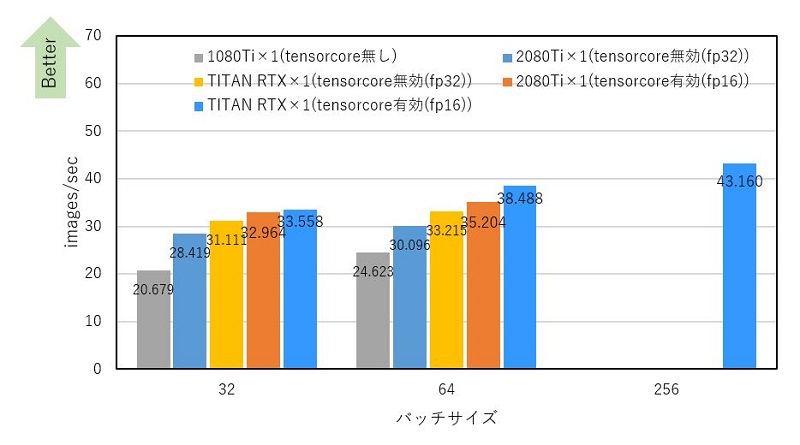
TensorCoreを有効にすることでバッチサイズ32、64ともに無効時に比べ高速化されたことを確認しました。また、使用するGPUメモリが無効時に比べ少なくなります。TITAN RTXで無効時にメモリ不足として実行できなかったバッチサイズ256がTensorCoreを有効にすることで実行できました。バッチサイズを上げるほどTensorCoreの効果が得られ高速化される[3]ことも測定結果から確認できました。
バッチサイズ64におけるTensorCore無効に対する有効時のスループットを比較しました。
TensorCore有無のスループット比較(2080 Ti、バッチサイズ64)
| GPU | TensorCore | 比率(対無効) |
| 2080 Ti | 無効 | 1 |
| 2080 Ti | 有効 | 1.2 |
TensorCore有無のスループット比較(TITAN RTX、バッチサイズ64)
| GPU | TensorCore | 比率(対無効) |
| TITAN RTX | 無効 | 1 |
| TITAN RTX | 有効 | 1.2 |
各GPU同士でTensorCore無効と有効を比較すると、2080 Ti、TITAN RTXは各々1.2倍の高速化がされました。学習率は、TensorCoreの有無に関わらず、ほぼ一致していました。
TensorCoreを使用するにあたりcuDNNの高速化を適用した段階では、上記の性能向上を確認できました。NVIDIA社の報告によれば、今回適用していないChainerの高速化テクニックを使用することにより、バッチサイズ64で最大3倍の高速化が図れる可能性があります。今後、今回適用したcuDNNの高速化に加えて、フレームワークChainerの高速化テクニックを適用した測定を実施し、TensorCoreの効果を確認していきたいと考えております。
[3]ChainerでTensorコア(fp16)を使いこなす https://www.slideshare.net/NVIDIAJapan/chainer-tensor-fp16
GPUの稼働状況を確認するため、GPU使用率が常時100%で動作している今回の学習中にGPUの温度、動作クロックを測定しました。(nvidia-smiを使用して測定)
2080 Ti×5の時の結果を下記に示します。
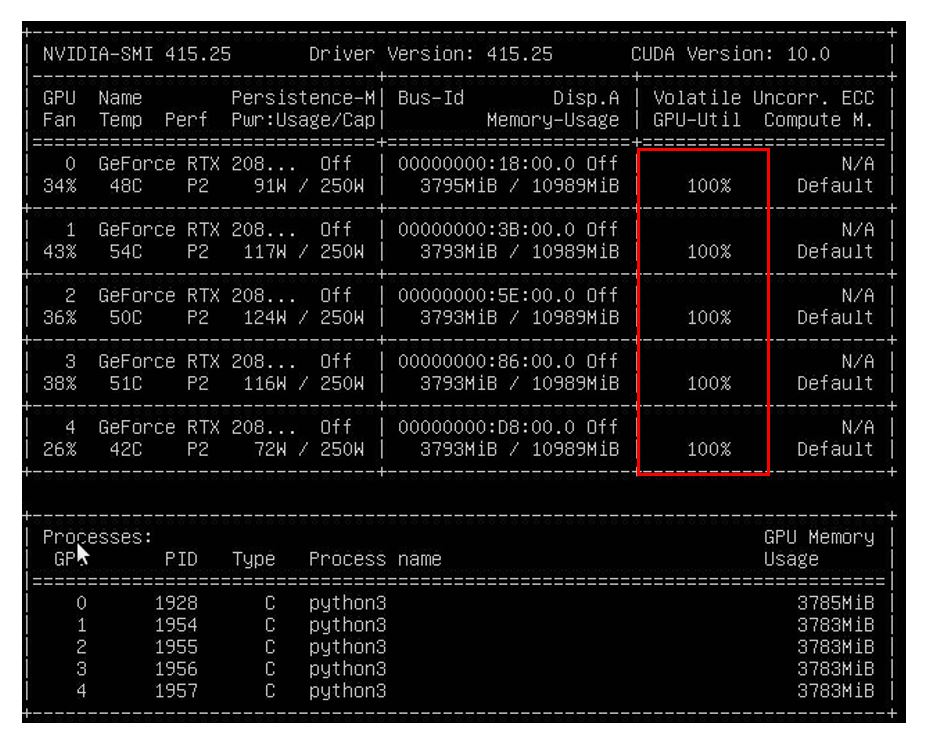
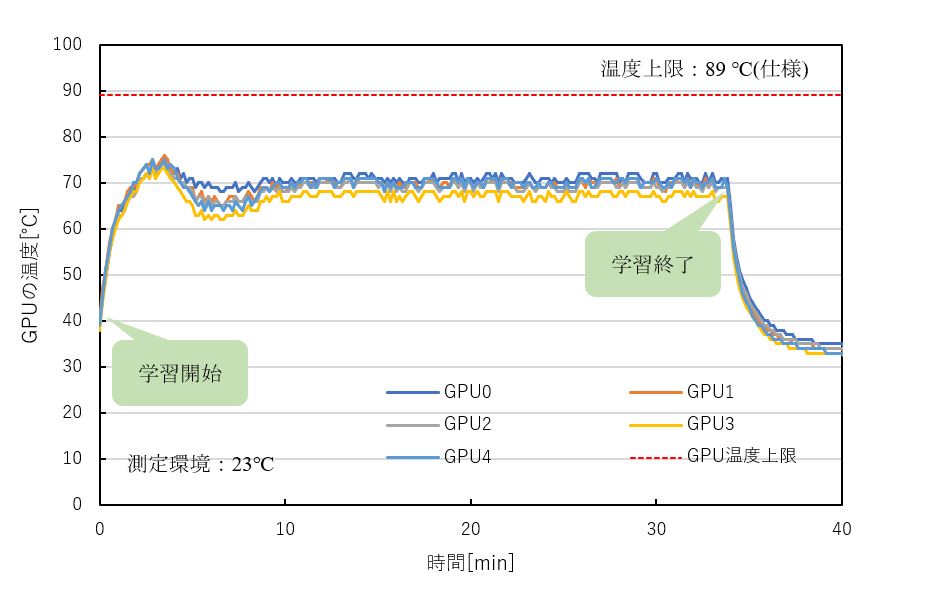
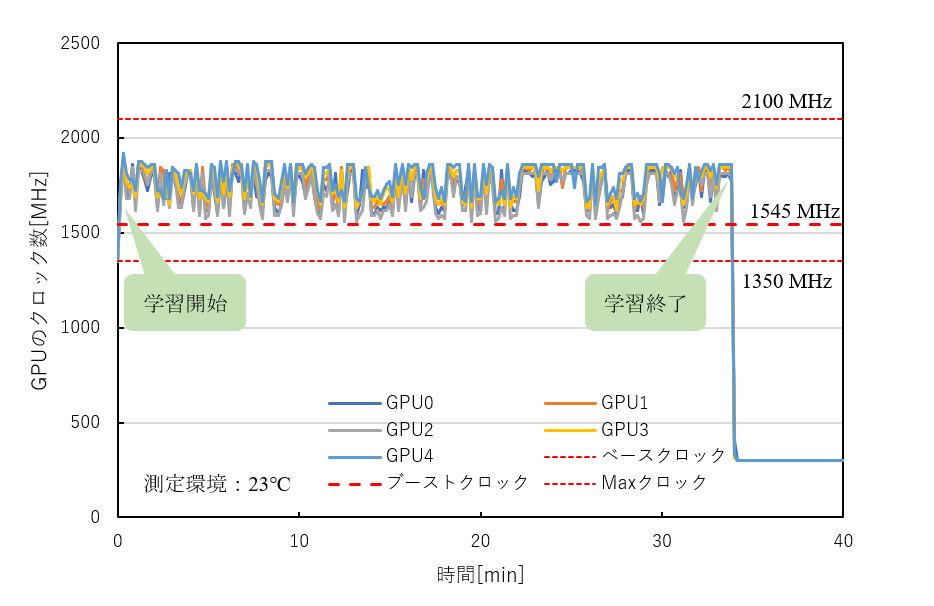
どのGPUも温度上限である89℃を大幅に下回る70℃付近で安定動作し、GPUブーストによりベースクロック1350 MHz、ブーストクロック1545 MHz以上のクロックで学習が行われていることが確認できました。(ブーストクロックはGPUブースト時の平均クロックのため、実測ではブーストクロック以上で動作しています。)
※GPU 10枚においても、全GPUが温度上限以下の80℃付近で動作し、ベースクロック以上(~1800 MHz程度)、GPU使用率100%で動作しております。
Turing世代のGPUである2080 TiとTITAN RTXを使用し、ImageNetの画像の一部を使用して学習時間を測定し、比較しました。
前世代であるPascal世代と比べ、アーキテクチャだけでなくCUDAコアの増加やメモリタイプの変更などハードウェア面の性能向上により、学習時間の高速化を確認できました。メモリを多く使う深いネットワークでの学習や、より大きなバッチサイズで学習を行いたい場合はTITAN RTXがおすすめです。
2080Tiを複数枚(最大10枚)搭載した環境で、温度、クロック数共に安定動作することも確認できました。
今回は、ディープラーニングのフレームワークであるChainerを使用しました。今後はImageNetの学習時間の測定だけでなく、機械学習の性能と品質を測るベンチマークである「MLperf」を使用した測定も実施していく予定です。
本レポートでご紹介しましたNVIDIA® TITAN RTX™、NVIDIA® Geforce® RTX 2080 Tiを搭載したサーバーおよびワークステーションをご提案いたします。GPUの搭載数はもちろん、ご要望や用途にあわせて構成いたしますのでお気軽にご相談ください。