『問題解決型』ハードウェアメーカー
ファナティック
-
- ファナティックの特長 ファナティックの特長
- /
- 製品&ソリューション 製品&ソリューション
- /
- 導入事例 導入事例
- /
- 最新ニュース 最新ニュース
- /
- ファナティックレポート ファナティックレポート
- /
- サポート サポート
- /
- 会社案内 会社案内
- /
- 採用情報 採用情報
2021.01.19 ベンチマークレポート
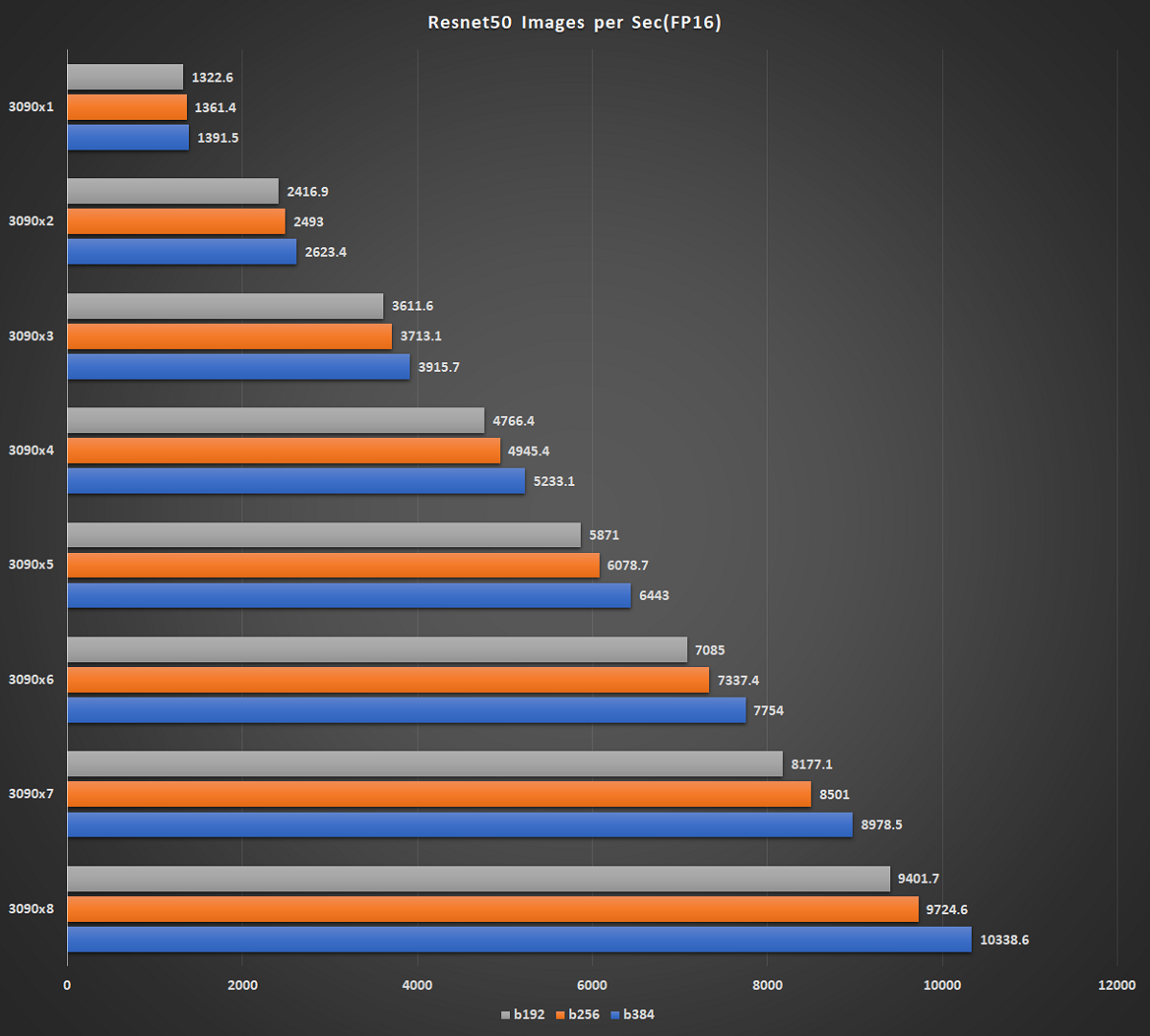
NVIDIA GeForce RTX 3090を8基搭載可能なモデルのリリースにあわせてディープラーニング検証結果を報告します。1~8まで搭載基数ごとのパフォーマンスをご覧下さい。
[総評]
これまで行ってきたGeForce RTX 3090複数搭載時のベンチレポートと同じくスケールアウトすることが確認できました。また、8基搭載時でバッチサイズを384にしたときには10338.6/sという結果が得られました。
[詳細]
・OS:Ubuntu 20.04.1 LTS
・GeForce Driver:455.45.01
・CUDA 11.1
・Docker 20.11.tf1.py3
ResNet50(fp16 Batch192/Batch256/Batch384)
※画像をクリックすると拡大します。
ResNet50(fp32 Batch192/Batch256/Batch384)
※画像をクリックすると拡大します。