『問題解決型』ハードウェアメーカー
ファナティック
-
- ファナティックの特長 ファナティックの特長
- /
- 製品&ソリューション 製品&ソリューション
- /
- 導入事例 導入事例
- /
- 最新ニュース 最新ニュース
- /
- ファナティックレポート ファナティックレポート
- /
- サポート サポート
- /
- 会社案内 会社案内
- /
- 採用情報 採用情報
2018.03.27 ベンチマークレポート
Volta世代のGPUでディープラーニングのベンチマーク(※)を実施しましたので紹介します。 Pascal世代であるGTX 1080Tiとも比較します。
※Volta世代ではTensorCoreによる高速化機構が追加されておりますが、今回のベンチマークはTensorCoreの効果を考慮したものではありません。
今回の学習で使用したGPUは以下の通り。
| Pascal世代 | Geforce GTX 1080Ti |
| Volta 世代 | NVIDIA TITAN V |
| Tesla V100(NVLink) x 8台 |
各GPUのスペックは以下の通りです。
| GTX 1080 Ti | TITAN V | Tesla V100 (NV-Link) |
|
| アーキテクチャ | Pascal | Volta | Volta |
| GP102 | GV100 | GV100 | |
| 倍精度FP性能(TF) | 0.35 | 7.4(※) | 7.8 |
| 単精度FP性能(TF) | 11.3 | 14.9(※) | 15.7 |
| ディープラーニング性能(TF) | – | 119(※) | 125 |
| CUDAコア | 3584 | 5120 | 5120 |
| クロック(MHz) | 1480 | 1200 | 1370 |
| boost時 | 1582 | 1455 | 1530(※) |
| メモリバンド幅(GB/s) | 484 | 652.8 | 900 |
| メモリサイズ | 11GB | 12GB | 16GB |
| メモリタイプ | GDDR5X | HBM2 | HBM2 |
| 電力(TDP) | 250 | 250 | 300 |
※一部性能はクロック(boost時)x演算器数からの推定
また、DIGITSでの学習は以下の内容で行っています。
| OS | Ubuntu 16.04 |
| CUDA | 9.0 |
| CUDNN | 7.1 |
| DIGITS | 6 |
| データセット | ネットワーク | フレームワーク | Epoch |
| Cifar10(Train) | GoogleNet | Caffe 0.16(nvidia fork) | 30 |
まずは、各GPUに対してDIGITSデフォルトバッチサイズで学習した結果を示します。
棒グラフ縦軸のSpeedは、画像枚数を時間で割ったものとしています。
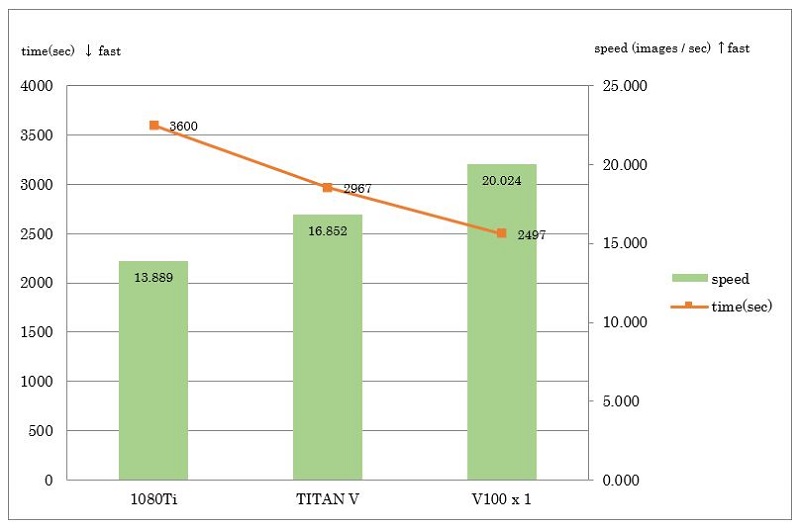
1080Tiと比較して、TITAN Vは約1.21倍、V100は1.44倍となっています。
デフォルトバッチサイズでは、メモリを最大限使用していませんでしたので、GPU実装のメモリサイズに応じてバッチサイズを変更して検証した結果が以下となっています。
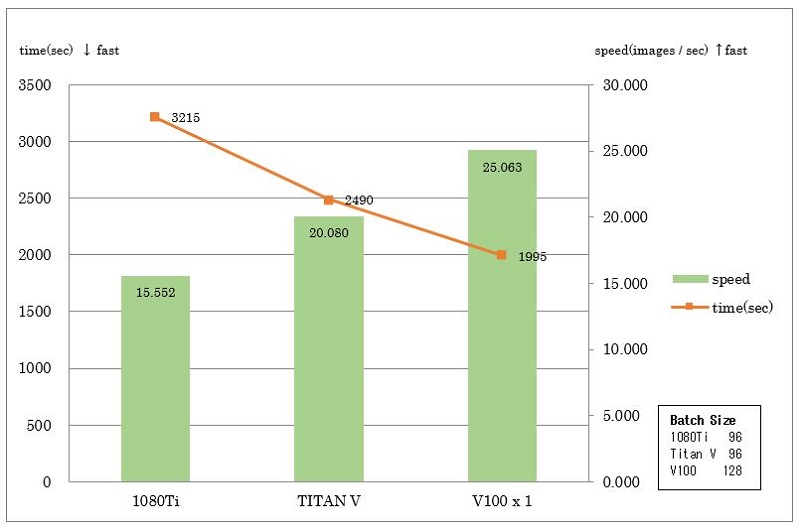
1080Tiと比較して、TITAN Vは約1.29倍、V100は1.61倍となっています。
※注 1080TiとTITAN Vは、バッチサイズを128にするとメモリ不足で実行不可。
次にMulti GPUにおける学習結果を紹介します。
まずはデフォルトバッチサイズでの実行結果を示します。
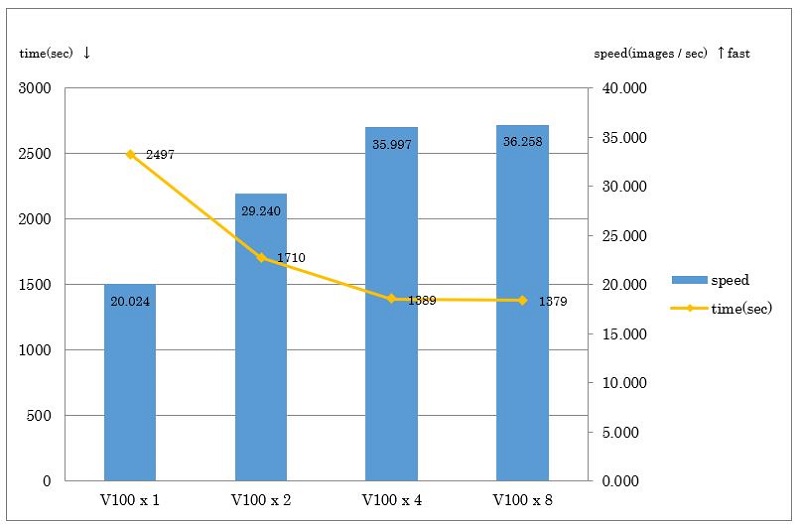
V100x1に対してV100x8では約1.81倍になっていますが、V100x4で頭打ちになっています。
次に、先ほどと同じく、メモリサイズに応じてバッチサイズを変更して測定した結果が以下となります。
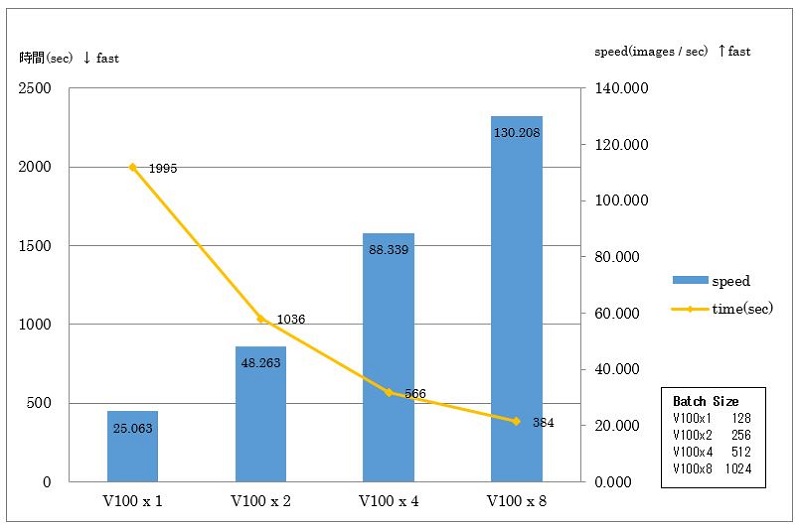
メモリサイズ(GPU数に比例)に応じてバッチサイズを変更することで、V100x1に対してV100x8では約5.19倍の学習速度になっていることを確認できています。
まとめ
今回はDIGITSによるCaffeの学習結果のみとなりましたが、これから機会があれば他のベンチマークも紹介していきます。
当社では、ディープラーニング向けにGPGPUやXeon Phiを実装した各種サーバやワークステーションをご用意しております。
また、各種フレームワーク(Caffe、Chainer、Torch、Tensorflow、Theano等)、ライブラリ等のインストールやカスタマイズの対応をさせて頂きますのでぜひご相談ください。
また、お客様の使用用途に合わせて自由にカスタマイズできます。CPU、メモリ、HDD、RAIDコントローラ、FC、infinibandなど仕様構成は変更・追加が可能です。




2020.12.17
【ベンチマーク(更新)】NVIDIA GeForce RTX 3090 4基 TensorFlow 学習ベンチマーク(ResNet50) ~RTX 3090 vs RTX 2080 Ti vs V100S 比較 ~
ベンチマークレポート
2017.06.20
Chainer + Deel による
簡単画像認識 デモ動画

2025.03.10
NVIDIA® H200 vs H100 NVLベンチマーク比較~TensorFlow学習ベンチマーク(ResNet50)~
ベンチマークレポート
2019.01.17
【ベンチマーク | 性能比較】Skylake-SP CPUをSPEC CPU2017でベンチマーク
ベンチマークレポート



