『問題解決型』ハードウェアメーカー
ファナティック
-
- ファナティックの特長 ファナティックの特長
- /
- 製品&ソリューション 製品&ソリューション
- /
- 導入事例 導入事例
- /
- 最新ニュース 最新ニュース
- /
- ファナティックレポート ファナティックレポート
- /
- サポート サポート
- /
- 会社案内 会社案内
- /
- 採用情報 採用情報
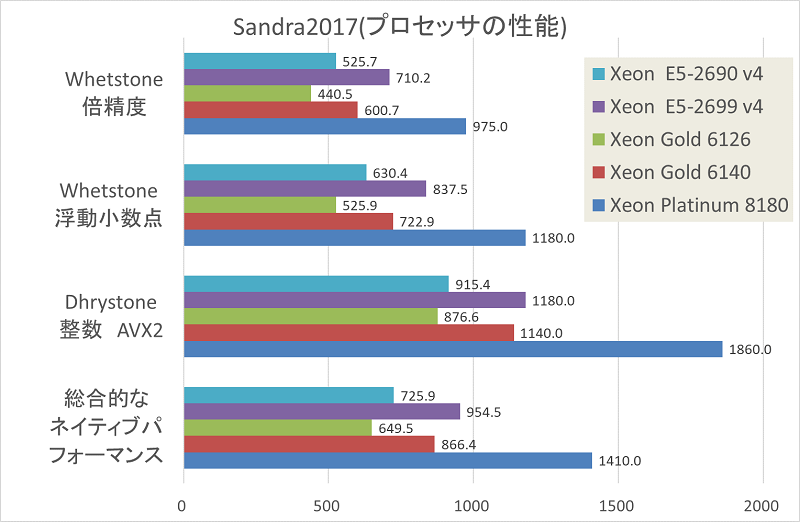
2017.09.25 ベンチマークレポート
以前のレポートにてDIGITSの使用方法を紹介しました。
今回は各GPUのDIGITSを使用したベンチマーク結果を紹介したいと思います。
DiGITSのインストール、使用方法につきましては、「NVIDIA® DIGITSで始めるディープラーニング」を参考にして下さい。
今回の学習で使用したGPUは以下の通り。
| Maxwell世代 | Geforce GTX TITAN X |
| Tesla M40 | |
| Pascal世代 | Geforce GTX 1080Ti |
| Quadro P6000 | |
| Tesla P100(NVLink) |
各GPUのスペックは以下の通りです。
| TITAN X Maxwell | Tesla M40 | Quadro P6000 | GTX 1080 Ti | Tesla P100 (NV-Link) |
|
| アーキテクチャ | Maxwell | Maxwell | Pascal | Pascal | Pascal |
| GM200 | GM200 | GP102 | GP102 | GP100 | |
| 倍精度FP性能(TF) | – | – | 0.37 | 0.35 | 5.3 |
| 単精度FP性能(TF) | 7 | 7 | 11.76 | 11.3 | 10.61 |
| 半精度FP性能(TF) | – | – | – | – | 21.22 |
| CUDAコア | 3072 | 3072 | 3840 | 3584 | 3584 |
| クロック(MHz) | 1000 | 948 | 1506 | 1480 | 1189 |
| boost時 | 1075 | 1114 | 1531 | 1582 | 1328 |
| メモリバンド幅(GB/s) | 336.5 | 288 | 432 | 484 | 549 |
| メモリサイズ | 12GB | 12GB | 24GB | 11GB | 12GB HBM2 |
| メモリタイプ | GDDR5 | GDDR5 | GDDR5X | GDDR5X | GDDR5X |
| 電力(TDP) | 250 | 250 | 250 | 250 | 300 |
また、DIGITSでの学習は以下の内容で行っています。(下記以外はデフォルト値)
| MNIST | Grayscale 28×28 |
| Cifar10(Train) | Color 128×128 |
| データセット | ネットワーク | フレームワーク |
| MNIST | LeNet | Caffe |
| Torch | ||
| Cifar10 | AlexNet | Caffe |
| Torch | ||
| GoogleNet | Caffe | |
| Torch |
実際に測定した結果は以下の通り。
各学習にて一番早い結果は青色で示しています。
| データセット | ネットワーク | フレームワーク | TITAN X | M40 | 1080Ti | P6000 | P100 |
| MNIST | LeNet | Caffe Torch |
0:00:50 | 0:01:09 | 0:00:39 | 0:00:39 | 0:00:48 |
| 0:01:12 | 0:01:30 | 0:01:13 | 0:01:00 | 0:01:39 | |||
| Cifar10 | AlexNet | Caffe Torch |
0:29:02 | 0:30:36 | 0:13:40 | 0:12:16 | 0:13:38 |
| 0:50:36 | 0:44:36 | 0:42:39 | 0:16:39 | 0:45:39 | |||
| GoogleNet | Caffe Torch |
1:35:27 | 2:05:22 | 0:49:11 | 0:47:52 | 0:51:36 | |
| 4:06:00 | 5:58:00 | 2:12:00 | 2:02:00 | 2:05:00 |
また、以下に結果をグラフ化しています。
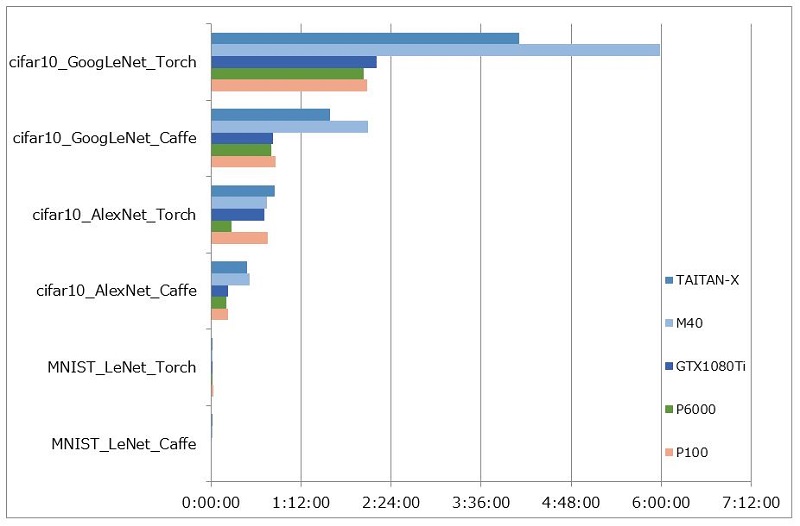
MNISTではデータセットが小さすぎるせいかほとんど差が確認できませんでしたが、
Cifar10の学習では、Maxwell世代に比べ、Pascal世代の結果が非常に良くなっていることがわかります。
Pascal世代間の比較では、P6000が一番良い結果になっています。
これに関しては、単精度浮動小数点演算においてはP100に対してコア数、クロック周波数が高いことや、カード上のメモリの容量により差が出ているのではないかと思われます。
また、NVLinkによるP100x2基と4基の学習も実施しました。
P100x1基と合わせて紹介します。
実際に測定した結果は以下の通り。
先程と同じく、各学習にて一番早い結果は青色で示しています。
| データセット | ネットワーク | フレームワーク | P100 | P100x2 | P100x4 |
| MNIST | LeNet | Caffe Torch |
0:00:48 | 0:01:12 | 0:01:08 |
| 0:01:39 | 0:05:11 | 0:03:10 | |||
| Cifar10 | AlexNet | Caffe Torch |
0:13:38 | 0:15:11 | 0:10:09 |
| 0:45:39 | 0:46:33 | 0:46:12 | |||
| GoogleNet | Caffe Torch |
0:51:36 | 0:47:00 | 0:34:25 | |
| 2:05:00 | 1:48:00 | 2:31:00 |
また、以下に結果をグラフ化しています。
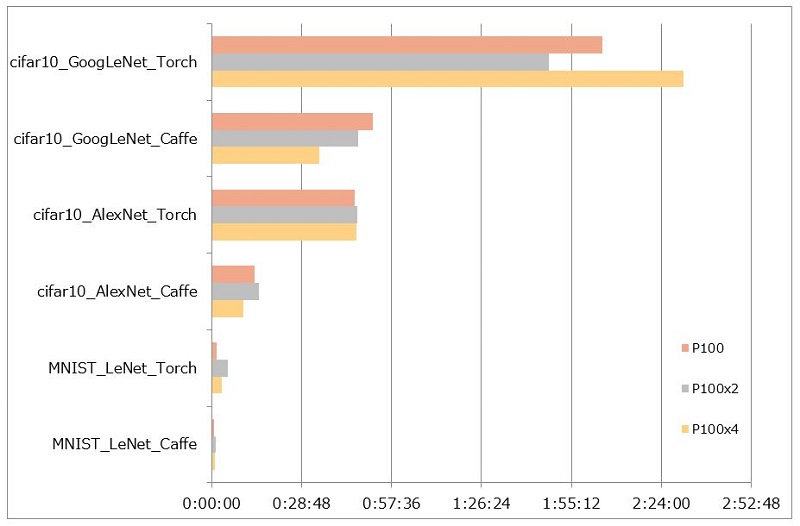
Cifar10では多少並列演算の効果は見られるものの、もう少し良い結果になると予想していました。
デフォルト設定での学習になっていますので、並列演算の効果を発揮するには並列化のオーバーヘッドを削減しデータセットの規模を大きくするなど工夫が必要になりそうです。
まもなく、Volta対応のCUDA9.0、Tensorflowに対応したDIGITS v6がリリースされます。
今回実施した学習結果とどのような違いがみられるのか、並列演算の効果は見られるのかを追ってレポートします。
【補足】
DIGITSのデータセット取得方法がv5から変更になっていますので注意が必要です。
DIGITS v5で学習を行う場合は、先のレポートと以下を参考にして下さい。
例)MNISTのデータセットを取得する場合
v4
$ cd /usr/share/digits/tools/download_data
$ mkdir ~/mnist
$ python main.py mnist ~/mnist
v5
$ mkdir ~/mnist
$ python –m digits.download_data mnist ~/mnist
※cifer10、cifer100も同様にダウンロードが可能です
当社では、ディープラーニング向けにGPGPUやXeon Phiを実装した各種サーバやワークステーションをご用意しております。
また、各種フレームワーク(Caffe、Chainer、Torch、Tensorflow、Theano等)、ライブラリ等のインストールやカスタマイズの対応をさせて頂きますのでぜひご相談ください。
⇒ GPU/Xeon Phi™製品
ご要望に合わせた高性能オーダーメイドが可能です。